
This post is a discussion on style transfer on audio signals. It also serves as support for the article “AUDIO STYLE TRANSFER”, done as product of my stay at Technicolor, under supervision of Alexey Ozerov, Ngoc Duong and Patrick Perez.
Style Transfer is defined as the creation of a novel sound from two others, the named “content” and “style”. It has been widely explored in image signals since the release of the seminal paper A Neural Algorithm of Artistic Style by Gatys et al.. The quintessential style transfer with images is the one where content refers to a portrait, style refers to a painting. The resulting image preserves the low frequency structures of the image, namely contours, of the content image. Conversely, high frequency details are kept from the style image, yielding an image that looks like the portrait, “painted” in a similar fashion as the style image. The figure below exemplifies the process.
The goal of this work is to step forward in adapting the procedure defined by Gatys et al. to audio signals. Unlike the original algorithm for images, we generalize the use of neural networks for any feature extractor. We have explored different neural networks and a feature extractor conceived for texture synthesis, developed by McDermott et al.. Our experiments show that the best results are obtained by initializing the result with the content sound (and not with noise, which is the original algorithm’s proposal). The use of a loss function for enforcing content was also deemed unnecessary.
Without further ado, here are two style transfers, obtained with our modifications and using the “Shallow, untrained network”. Note how the style sound alligns itself to the melody of the content.
Content - Music | Style - Bongo | Result | ||
Style - Applause | Result | |||
Below, some spectograms of different content/style combinations, using four different feature extractors. A more detailed discussion is proposed in the article.
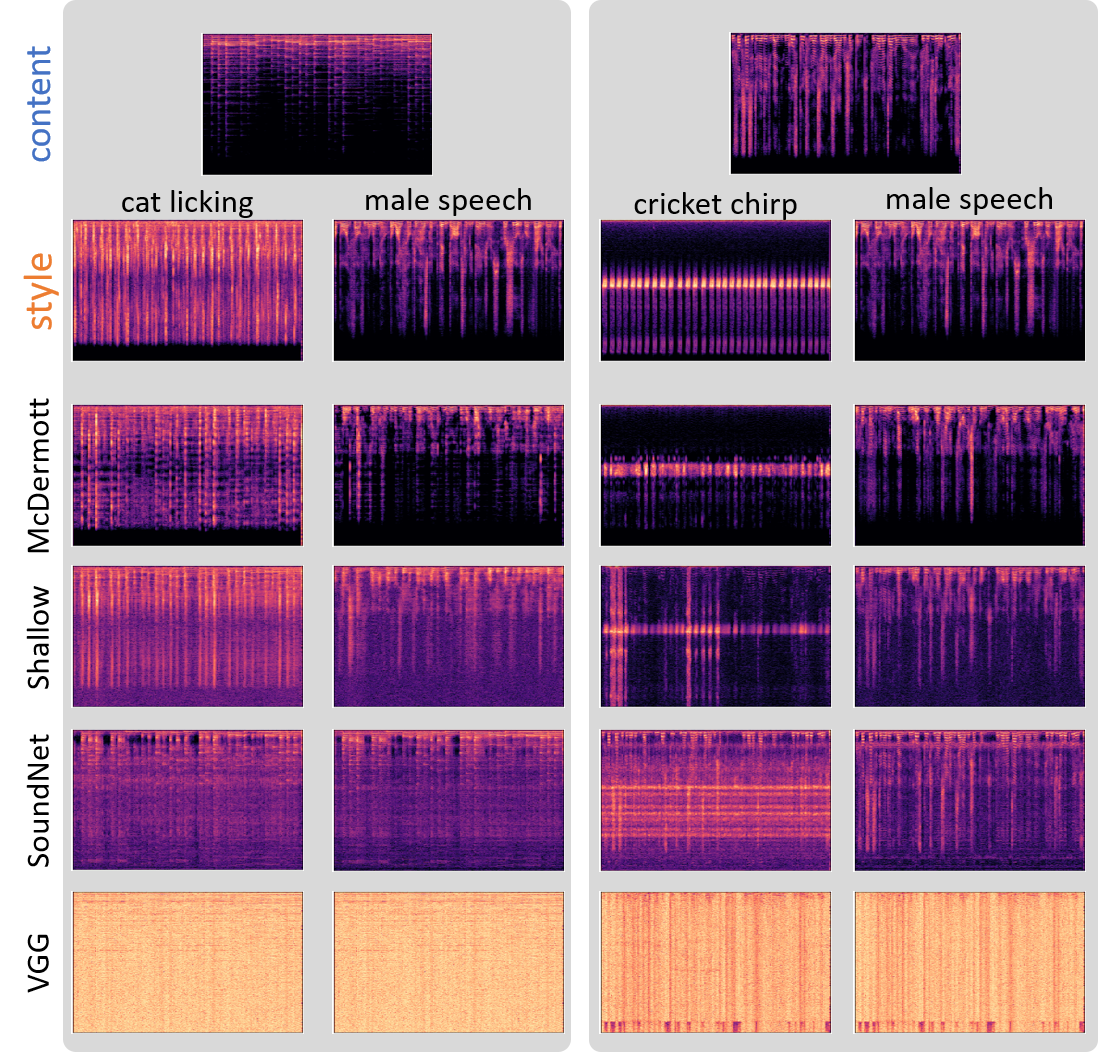
In addition, the following table corresponds to the audios of the spectrograms presented in the paper. Note that McDermott and Shallow are the only ones with pleasing results. SoundNet and VGG are included here for completeness. SoundNet’s results are unapealling however hearable. VGG’s results are almost pure, although some of the content’s original sound can be heard. Their results are the most interesting ones, where melody is preserved, while combined with style.
| Method | content - music | content - female speech | ||
style - cat licking | style - male speech | style - cricket chirp | style - male speech | |
| McDermott | ||||
| Shallow | ||||
| SoundNet | ||||
| VGG [ATTENTION! NOISY.] | ||||
As you can see, results vary significantly throughout feature extractors, and it is interesting to compare the McDermott and the Shallow network. Although the features extracted are very dissimilar in nature, they both produce similar results, with Shallow being better at placing style sounds, McDermott in being faithful to the original style texture.
Lots of questions are still open: what is style, what is content, which is the best way to preserve it, what is the best feature extractor. If you would like to discuss, feel free to contact me.